SSA记录博客
0. 前置准备(可选)
基础知识点
SSA是什么:
静态单赋值,每次赋值定义一个新的变量,每个变量(包括原始变量和新创建的变量)都只有唯一的一次定义
LLVM中的SSA怎么形成的:
MemorySSA 通过mem2reg到value SSA
内存:对于每个变量,只要在定义他的时候,为他在内存中划分空间存入,在使用他的时候在取出来,这样就可以达到 SSA 的效果。可以少插入很多不必要的phi函数,对前端生成的速度和难度也是一个考量。
SSA有什么好处:
dense分析:要用个容器携带所有变量的信息去遍历所有指令,即便某条指令不关心的变量信息也要携带过去
sparse分析:变量的信息直接在def与use之间传播,中间不需要遍历其它不相关的指令。
源程序中对同一个变量的不相关的若干次使用,在SSA形式中会转变成对不同变量的使用,因此能消除很多不必要的依赖关系
消除无法到达的基本块
工作表算法
将entry放入worklist
每次循环,从worklist中随机拿出一个基本块,将它的visited标记为1
将被拿出的基本块的true_block和false_block添加进worklist
将这个被随机拿出的基本块移除worklist
把visited为0的块都删除
1. 计算支配信息
节点m支配节点n当且仅当从流图入口entry到n的所有路径都经过m,记做:m dom n
在支配树上,如果一个节点n的父节点是m,则称m是n的立即支配节点,记做m=idom(n)
简易版:求交集得dom再往后算idom(略)
将entry自身加入entry的dom
将所有会被访问到的基本块加入allNode这个HashSet中
除了entry外,先默认每一个基本块的dom都是allNode,即放入全集
除了entry:根据ir顺序遍历所有基本块,对于每一个遍历到的基本块,对于它的所有前驱块:
将所有前驱块的必经基本块dom求交集,求完之后再并上自己,就是当前块的dom

很显然,支配关系具有自反性,反对称性和传递性,所以支配关系是G上的一个偏序关系
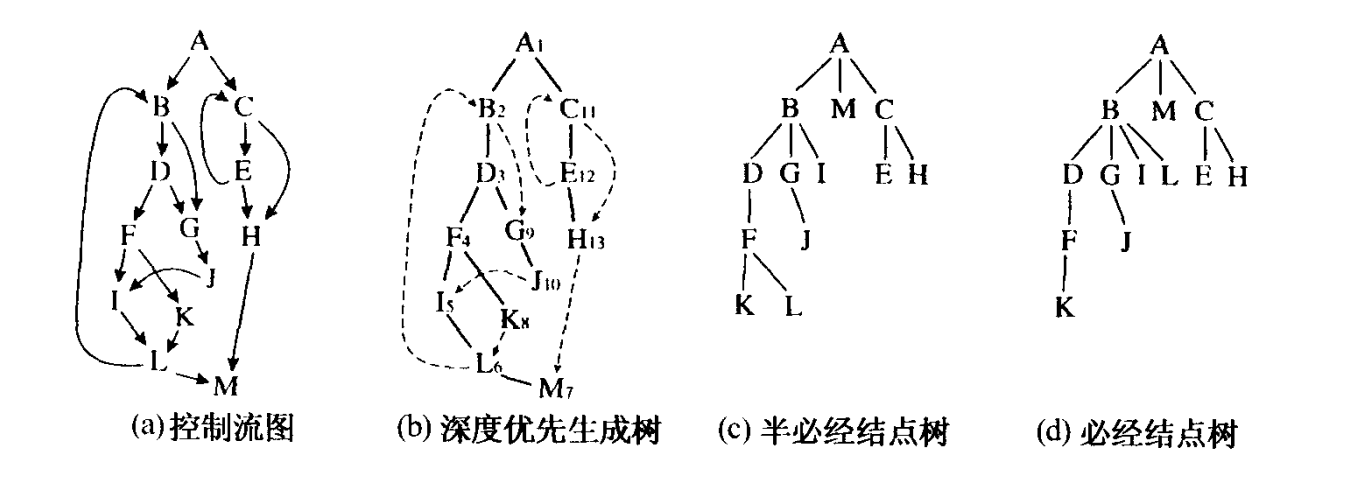
高效版:Lengauer-Tarjan算法得支配树
通过半必经结点定理和必经结点定理构造支配树
时间复杂度为 O(nlogn)
基本思想:
通过DFS构建搜索树,并计算出每个节点的时间戳。
根据半必经点定理,按照时间戳从大到小的顺序计算每个节点的半必经节点。
根据必经点定理,按照时间戳从小到大的顺序,把半必经节点≠必经节点的节点进行修正。
(1) 通过编号得出深度优先生成树
如果在生成树中,a是b的真祖先,则dfnum(a) < dfnum(b)
注意b图标号,一分支右边的标号一定都比左边的大
dfs深度遍历给num即可
(2) 从N最大的block开始
1st. 找每个block的半必经结点
半必经结点:在搜索树T上点y的祖先中,通过非树枝边 可以到达y的深度最小的祖先x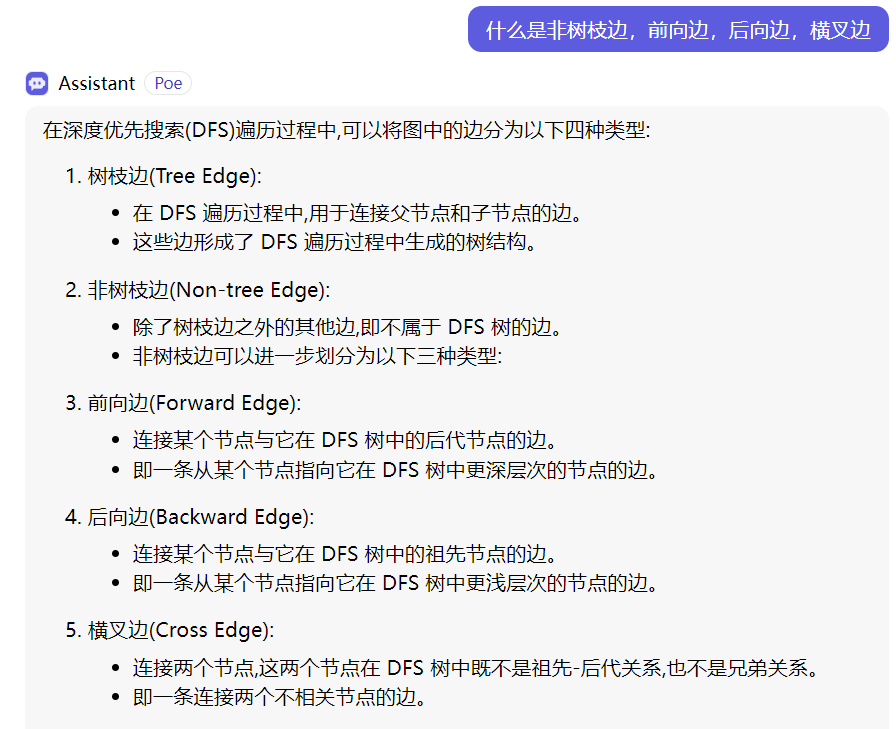 其中横叉边的起点永远大与终点编号。
其中横叉边的起点永远大与终点编号。

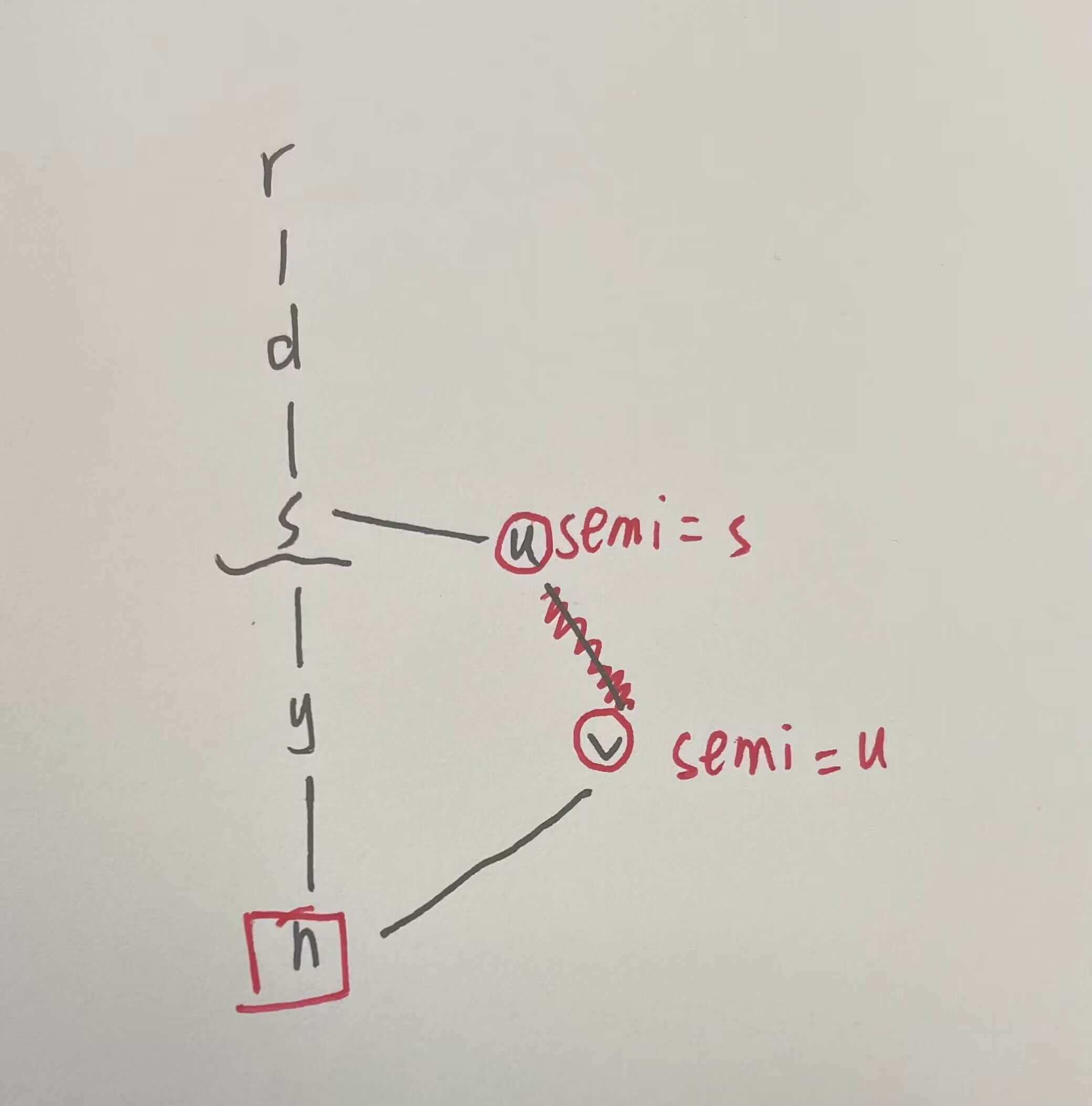
在没有旁路干扰的情况下,n的半必经结点其实就是它的上一级祖先
注意对于第二点“每个祖先”的理解:
在计算n的半必经结点时(v不是n的祖先时),祖先数组ancestor记录下的只有ancestor[v] = u, ancestor[u] = s,而没有记录到s, ancestor[s] = NULL,而每次while的临界条件是ancetor[x] != NULL,所以在v向上遍历的过程中,只遍历的到u,不会再向上面的祖先s,d,r遍历。
所以这里计算n的半必经结点时,n的第一个候选是真祖先y,第二个候选是semi(v) = u,第三个候选是semi(u) = s,最终选择s
2nd. 添加bucket, ancestor
将半必经结点相同的block添加到一个bucket中,并加上n和y的ancestor关系
这样做的用意是?(方便找semi信息吧,一个semi block的blocks一起处理,没有细看,TODO 不知道和方便路径压缩有没有关系呢)
3rd. 填充idom
必经结点定理:

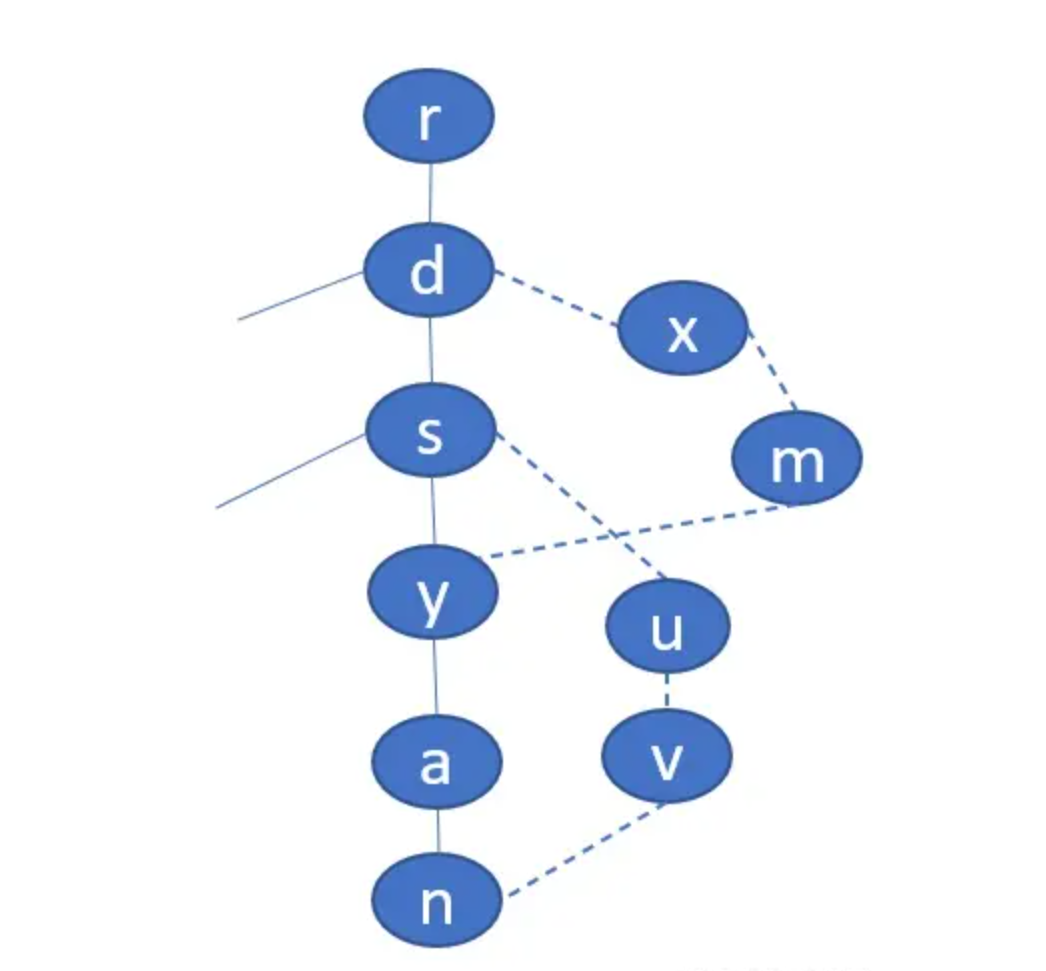
以此图为例说明,找n的必经结点:
semi(n) = s,在s之下和n之上的生成树路径(y、a、n,注意没有s),我们找到了y,它的semi(y)是d,dfnum最小,所以dfnum(y) != dfnum(n),n的idom便等于y的idom,即等于d
又比如找y的必经结点,semi(y) = d,在s、y路径上,每个结点半必经结点中最小的半必经结点就是d,即semi(y) = semi(y),所以idom(y) = semi(y),就是d
具体代码实现

普通情况:求a的idom,以s --y--a为例,semi(a) = y, ancestor[a] = y, AncestorWithLowestSemi得到的y还是a(第一次相等的不变,ancestor[y] = s还未加入,无法再向上遍历),于是y = v, idom[a] = y
情况1:求y的必经结点,在讨论y时,它的parent是s而不是d,所以在讨论y这一轮不会参加必经结点计算,而需要等到s时,s的p是d,才会一起计算s和y。到s时此处计算y,AncestorWithLowestSemi是s(如果主干直线上还有别的结点,就会一路算完每个结点返回最小semi的结点),semi(s)还是d,于是idom(y) = 此时的p即d
情况2:求n的必经结点。在讨论n时,它的parent是a而不是s,所以在讨论n这一轮不会参加必经结点计算,而需要等到y时,y的p是s,才会计算n。此时,AncestorWithLowestSemi是y,
semi[y] != semi[n], semi[y]还没被算出来,但是semi[n] != NULL,于是samedom[n] = y,指n的idom与y的idom相同,但现在y的idom还没算出来,将计算延迟。后续:
在y的idom算出来之后,将y的idom值赋给n的idom
根据idom构造一个支配树
d图比如BMC的iDom都是A,所以这样建支配树
给每个block初始化一个结构(下为随意举例)
struct _DomNode{ BasicBlock *parent; BasicBlock *block; HashSet *children; //保存DomNode*,保存直系children //lsy HashSet *all_children; //以该结点为root的sub-tree的所有孩子 bool visited; bool alpha; //是不是初始化就加进piggybank中的,如果为true,就是初始化就在的 bool inphi; int level; };从头遍历每个block,每个block的parent是它的iDom,add使得它的iDom的children有block
2. 生成phi函数
0. 前置non-local的semi-pruned SSA
we only insert a f -function for a variable v at the beginning of a block if v is live on entry to that block, 需要先求live set,因为如果是后面没有被用到的变量,根本不需要生成phi
但是它开销大,其实也可能有extra phi会对比如value numbering更好,所以又有了semi-pruned SSA。当然主要是开销大
semi-pruned SSA
有一些value只def和use在同一个基本块中
non-local:在一个block的entry就有的变量
被def过了就不能进Non-local了,non-local就是在该基本块内出现它的def前就被用过了
The non-local set is initialized once; the killed set is reset for each block

优化phi 函数生成:只有non-locals才需要放置phi函数
(1) 算出DF
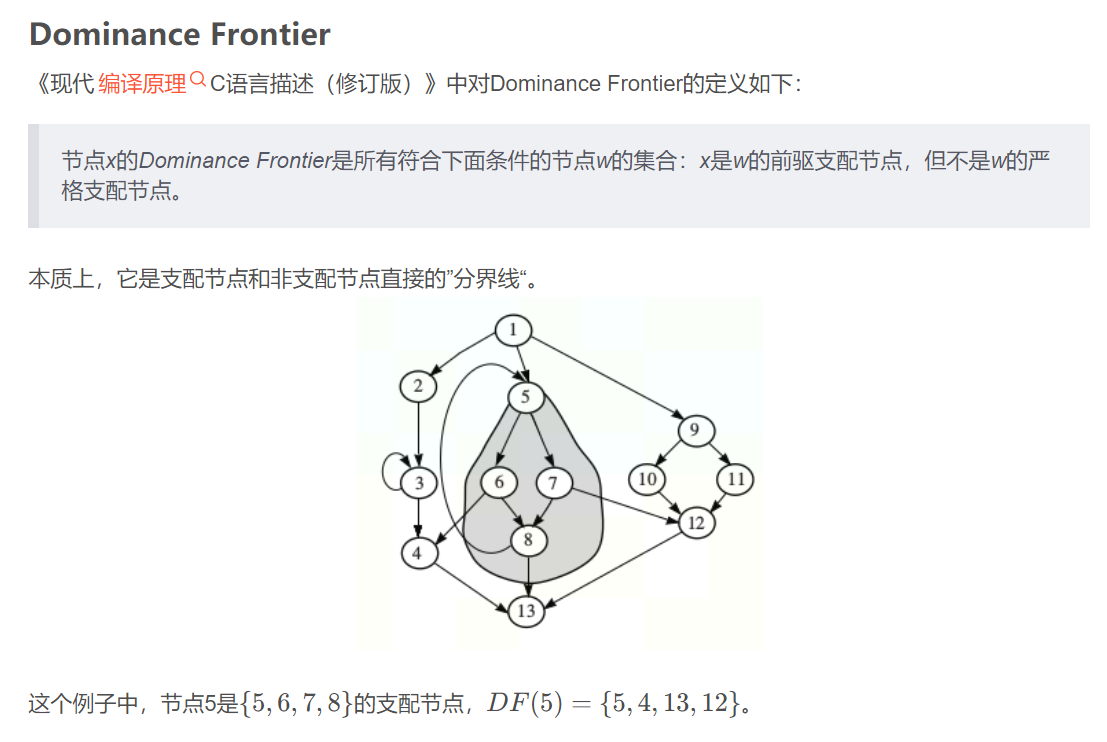
支配边界Dominance Frontier:
a. 简易遵从定义版
如果是用的简易版本,每个block记录了dom的block:
将全集添加到allBlocks
让tempSet内容等于allBlocks
就用书上x是w的前驱支配节点,但不是w的严格支配节点做:
举例:5是4的一个前驱(6)的支配节点,但不是4的支配节点;5是5的一个前驱(8)的支配节点,是5的支配节点,但不是5的严格支配节点
HashSetFirst(allBlocks); for(BasicBlock *X = HashSetNext(allBlocks); X != NULL; X = HashSetNext(allBlocks)){ X->df = HashSetInit(); HashSetFirst(tempSet); for(BasicBlock *Y = HashSetNext(tempSet); Y != NULL; Y = HashSetNext(tempSet)){ if(HashSetFind(Y->dom,X) && Y->true_block != NULL){ if(!HashSetFind(Y->true_block->dom,X) || Y->true_block == X){ HashSetAdd(X->df,Y->true_block); } } if(HashSetFind(Y->dom,X) && Y->false_block != NULL){ if(!HashSetFind(Y->false_block->dom,X) || Y->false_block == X){ HashSetAdd(X->df,Y->false_block); } } } }
b. 遍历必经节点树算DF
这也是一个接近

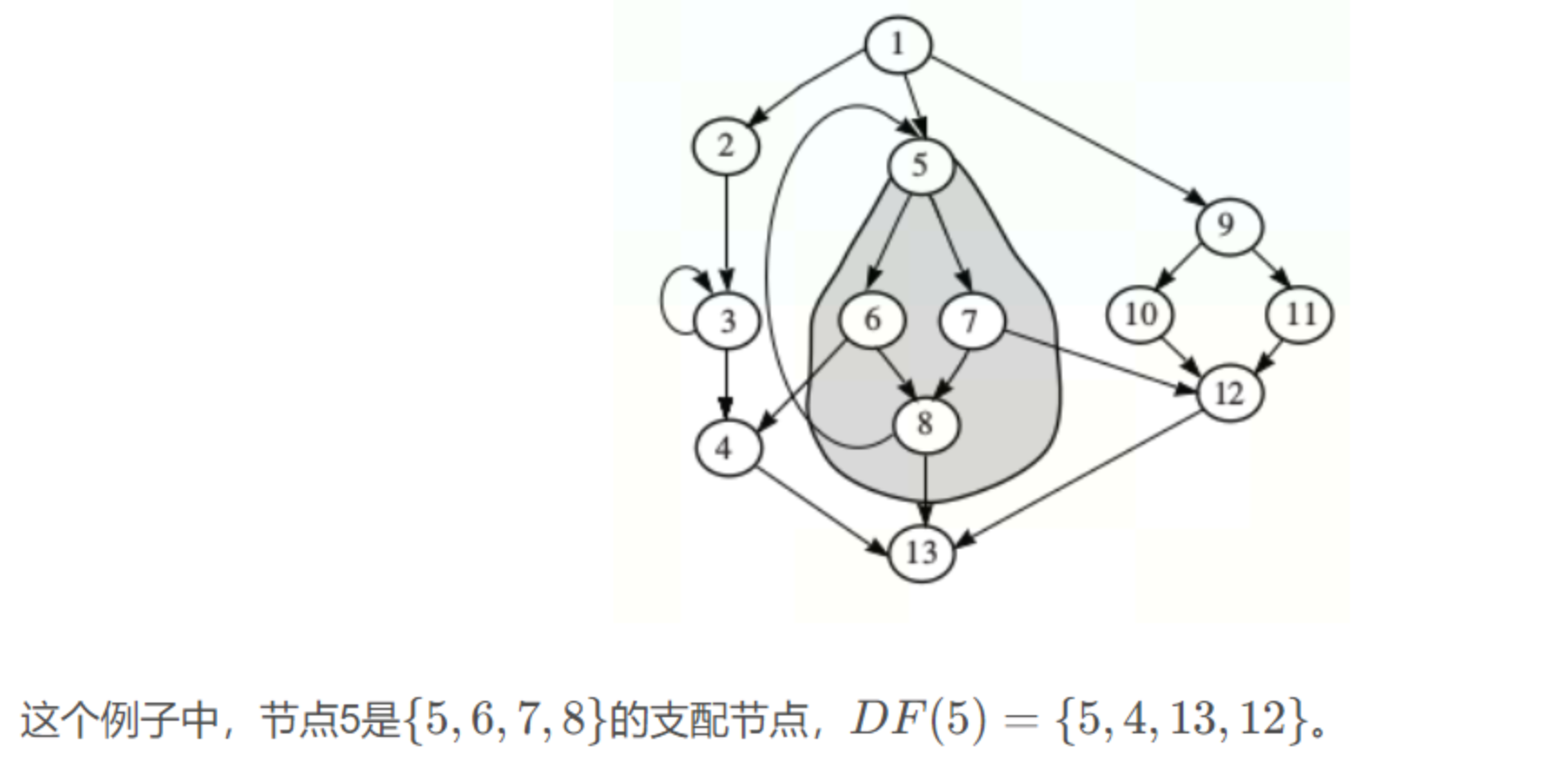
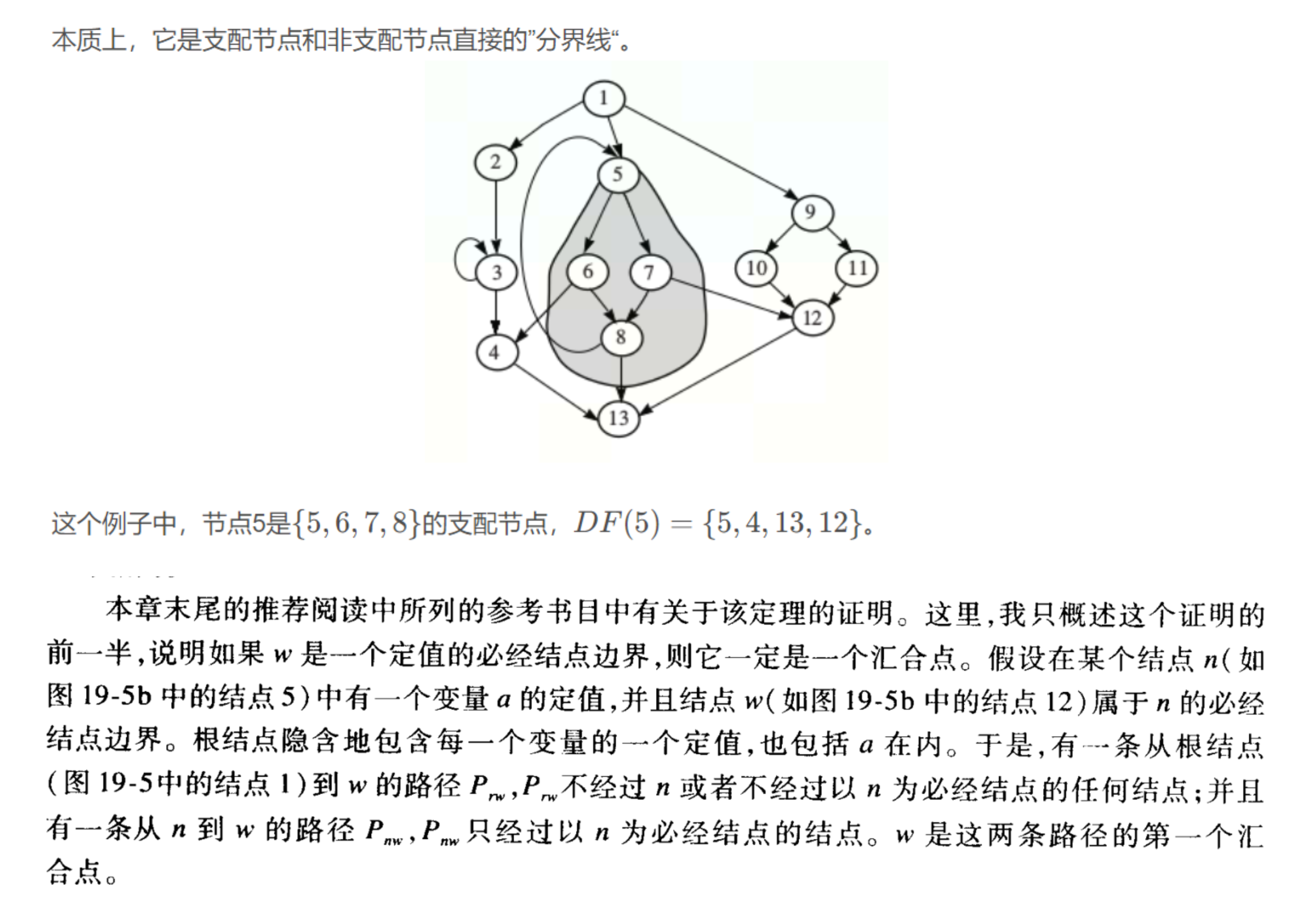
例:求DF[5]:
DF local[5]:5的后继6和7都以5为idom,所以这一步无
需要先求DF[6]和DF[7]和DF[8](必经结点树中的儿子)
DF[6]:
6的后继4 + 8
无儿子
DF[7]:
7的后继12 + 8
无儿子
DF[8]:
8的后继5 + 13
——>> 5的DF是5,4,12,13
总结一下这个算法,求DF[n]:第一部分DF local是关键,就是看CFG直接的几个后继,如果它的idom不是n,说明肯定有其他路径到它,满足边界含义(按定义推的话:它的前驱n是自反支配的,但是n不是它的必经),它肯定是DF。
第二部分看必经结点树的儿子:递归,因为如果CFG中的结点必经n的儿子,肯定也必经n,如果这个到达DF[儿子]中某一节点不必经n的儿子,则肯定满足DF
潜在的O(N2)复杂度
c. 论文O(n)算IDF:
flowgraph:G = (N, E, START, END)
N:set of nodes
E:set of edges
START:a distinguished start node
END:a distinguished end node
|S|:number of elements in the set
subTree(x):a dominator sub-tree rooted at x;
x.level:the level number(tree depth) of x
DF(x):x dominates a predecessor of y, but x does notstrictly dominate y
IDF(S):DF for a set of nodes S(递增顺序)
D-edges:dominator tree edges
J-edges:
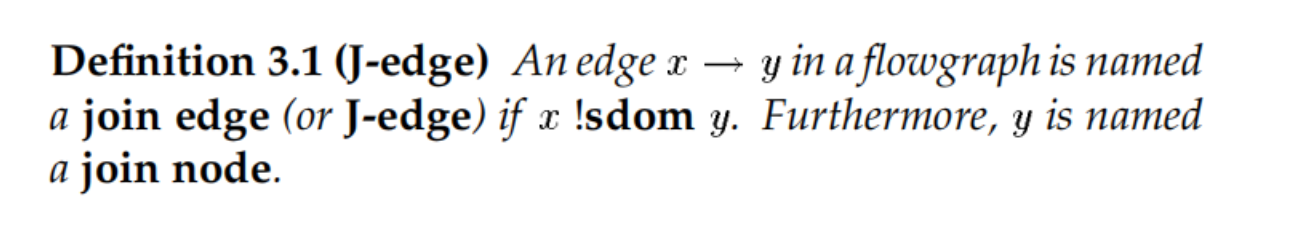
insert J-edge :O(E)
properties:
dj图中的边数小于相应流图中的节点数和边数之和
y属于DF(x),则y.level <= x.level(——>> 在找DF(x)时,只需要看level值<=x的node)
定理2证明:


y in DF(x) 等价于 (有一个Node z,满足z in SubTree(x) and j-dege( z ---> y ),使得y.level <= x.level)
Lemma 3.1(核心):
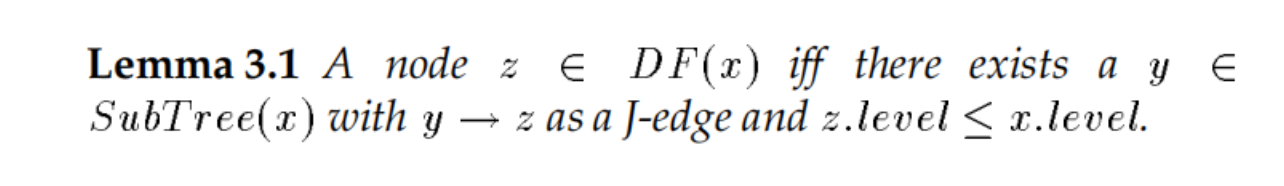
核心定理证明:

得出的算法:

structure PiggyBank:keep the candidate nodes in the order of their respective levels:
PiggyBank:an array of list of nodes, with index i storing nodes of level i
InsertNode():在正确的level number insert
GetNode():returns the node whose level number is the maximum of all nodes currently stored
visit():查找相关D-edge和J-edge
最终达成:输入一个或多个结点(visited标志位保证多个结点计算时不会重复计算),可动态计算返回指定的一个或者多个Block的DF集合
详细算法详见论文及自己的实现代码。
(2) 找出所有def ( store )和use( load )语句
function的结构中有一个loadSet的map,保留了每个被load的value的loadset(set),loadSet中装的是这个value的load语句出现的基本块。
function的结构中有一个storeSet的map,保留了每个store到的value的storeSet(set),storeSet中装的是store到value的store语句出现的基本块(defBlock)。
(3) 根据DF插入phi
原理:
首先不是每个汇合点都需要加phi,汇合点指的是前驱个数超过1个的结点。
比如这个图4的phi就没必要加,因为a2,a1是一样的
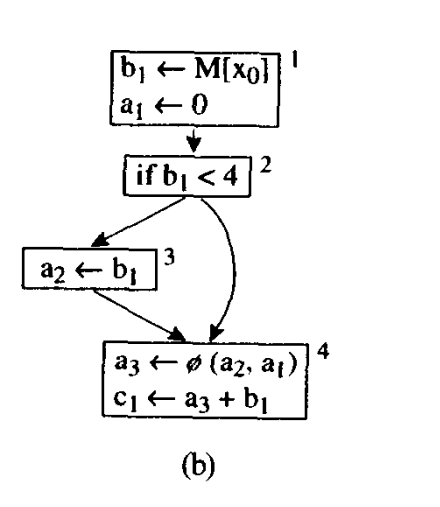
使用DF可行原因:
具体算法实现:

遍历所有有def的value,拿到每个value对应的storeSet
对于每一个value:
将storeSet的block一个个拿出来并从storeSet中移除,拿出它的df,遍历所有df,在df的每个block上面放置phi函数,并将每个df的block加入storeSet。
插入phi函数的时候,每个phi对应映射一下对应的alloca
结果举例:
DF:
比如在基本块10中有store i32 %12,i32* %5,align 4,则在b6和b36都有%5的phi ir
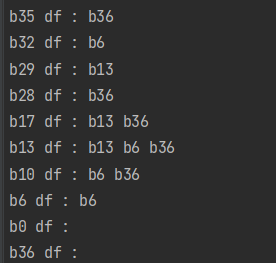
2(id) :@graph=dso_local global [30 x [30 x i32]] zeroinitializer, align 4
1(id) :@store=dso_local global [30 x i32] zeroinitializer, align 4
3(id) :define dso_local i32 @is_clique(i32 %0) #0{
4(id) : %2 = alloca i32,align 4
5(id) : %3 = alloca i32,align 4
6(id) : %4 = alloca i32,align 4
7(id) : %5 = alloca i32,align 4
8(id) : store i32 %0,i32* %3,align 4
9(id) : store i32 1,i32* %4,align 4
11(id) : br label %6
12(id) :6: ; preds = %32 %0
0(id) :id 6, val %4
0(id) :id 6, val %5
13(id) : %7 = load i32,i32* %4,align 4
14(id) : %8 = load i32,i32* %3,align 4
15(id) : %9 = icmp slt i32 %7,%8
16(id) : br i1 %9,label %10,label %35
17(id) :10: ; preds = %6
18(id) : %11 = load i32,i32* %4,align 4
19(id) : %12= add nsw i32 %11,1
20(id) : store i32 %12,i32* %5,align 4
22(id) : br label %13
23(id) :13: ; preds = %29 %10
0(id) :id 13, val %5
24(id) : %14 = load i32,i32* %5,align 4
25(id) : %15 = load i32,i32* %3,align 4
26(id) : %16 = icmp slt i32 %14,%15
27(id) : br i1 %16,label %17,label %32
28(id) :17: ; preds = %13
29(id) : %18 = load i32,i32* %4,align 4
30(id) : %19=getelementptr inbounds [30 x i32],[30 x i32]* @store, i32 0,i32 %18
31(id) : %20 = load i32,i32* %19,align 4
32(id) : %21=getelementptr inbounds [30 x [30 x i32]],[30 x [30 x i32]]* @graph, i32 0,i32 %20
33(id) : %22 = load i32,i32* %5,align 4
34(id) : %23=getelementptr inbounds [30 x i32],[30 x i32]* @store, i32 0,i32 %22
35(id) : %24 = load i32,i32* %23,align 4
36(id) : %25=getelementptr inbounds [30 x i32],[30 x i32]* %21, i32 0,i32 %24
37(id) : %26 = load i32,i32* %25,align 4
38(id) : %27 = icmp eq i32 %26,0
39(id) : br i1 %27,label %28,label %29
40(id) :28: ; preds = %17
41(id) : store i32 0,i32* %2,align 4
42(id) : br label %36
43(id) :29: ; preds = %17
44(id) : %30 = load i32,i32* %5,align 4
45(id) : %31= add nsw i32 %30,1
46(id) : store i32 %31,i32* %5,align 4
47(id) : br label %13
48(id) :32: ; preds = %13
49(id) : %33 = load i32,i32* %4,align 4
50(id) : %34= add nsw i32 %33,1
51(id) : store i32 %34,i32* %4,align 4
52(id) : br label %6
53(id) :35: ; preds = %6
54(id) : store i32 1,i32* %2,align 4
55(id) : br label %36
56(id) :36: ; preds = %35 %28
0(id) :id 36, val %2
0(id) :id 36, val %5
57(id) : %37 = load i32,i32* %2,align 4
58(id) : ret i32 %37
59(id) :}3. 变量重命名

(1) 遍历一遍第一个基本块,用map装入每个变量和它对应的stack
(2) 重命名
如果没有alloca,就不需要重命名
DFS遍历支配树,对每个根块进行处理后进行重命名(以基本块为单位)
用一个map计算每个变量和它的定值次数,初值默认为0
遍历基本块中每个语句:
非phi的每一次使用( load ):用这个变量stack的top替换
变量的每一次定值( store ):将它压入stack,并在该语句中用压入stack的新值替换这个语句中的定值,这个变量的defineTimes++
如果有phi ir(一定在一个基本块最前),%phi = alloca值,则将phi左值也作为定值入栈,definetimes++
维护该基本块所有的后继基本块中的phi指令 修改对应alloca变量的phi函数中的参数,新建一个pair加入这个phi的pairSet,其中值为该变量栈的top值,注意先判断有没有值,如果没有值的话是undef
DFS遍历支配树的其他块(此时栈内容是继续往下用的)
将每个变量的栈的所有内容清空了
tips:在重命名时,每次一个block,可以维护一个list记录哪些变量有了def,对于有def的变量,不用每次都压栈,可以直接覆盖(因为下面的值用不到了,但是最初值是不能覆盖的,因为可能后面的Block会用),这也会加快最后弹出栈的速度
*4. pruned-SSA
SSA book的伪代码:
本质上意思还是删除后面没用到的变量的phi
stack is used to store useful and unprocessed variables defined by φ-functions.

第一次遍历支配树每个块:
phi ir:默认左值的useless为true
其他ir:lhs,rhs如果是Phi的左值,将这个Value的Useless设置为false,并将它入栈
遍历栈,在栈里的都是用过但还未处理的phi左值
一个个拿出左值的pairSet,如果define也是phi左值并且之前标志为了useless = true,将它改为false,并继续入栈
第二次遍历(对整个函数的一条条ir),将左值useless为true的phi ir删掉
5. phi函数消除
a set of phi-related variables (source and destination) as a phi-web
最简单的方法: split all critical edges, and then replace φ-functions by copies at the end of predecessor basic blocks(在基本块的末尾进行copy operation)
(1) 边分割
从图b到图c就是边分割的过程
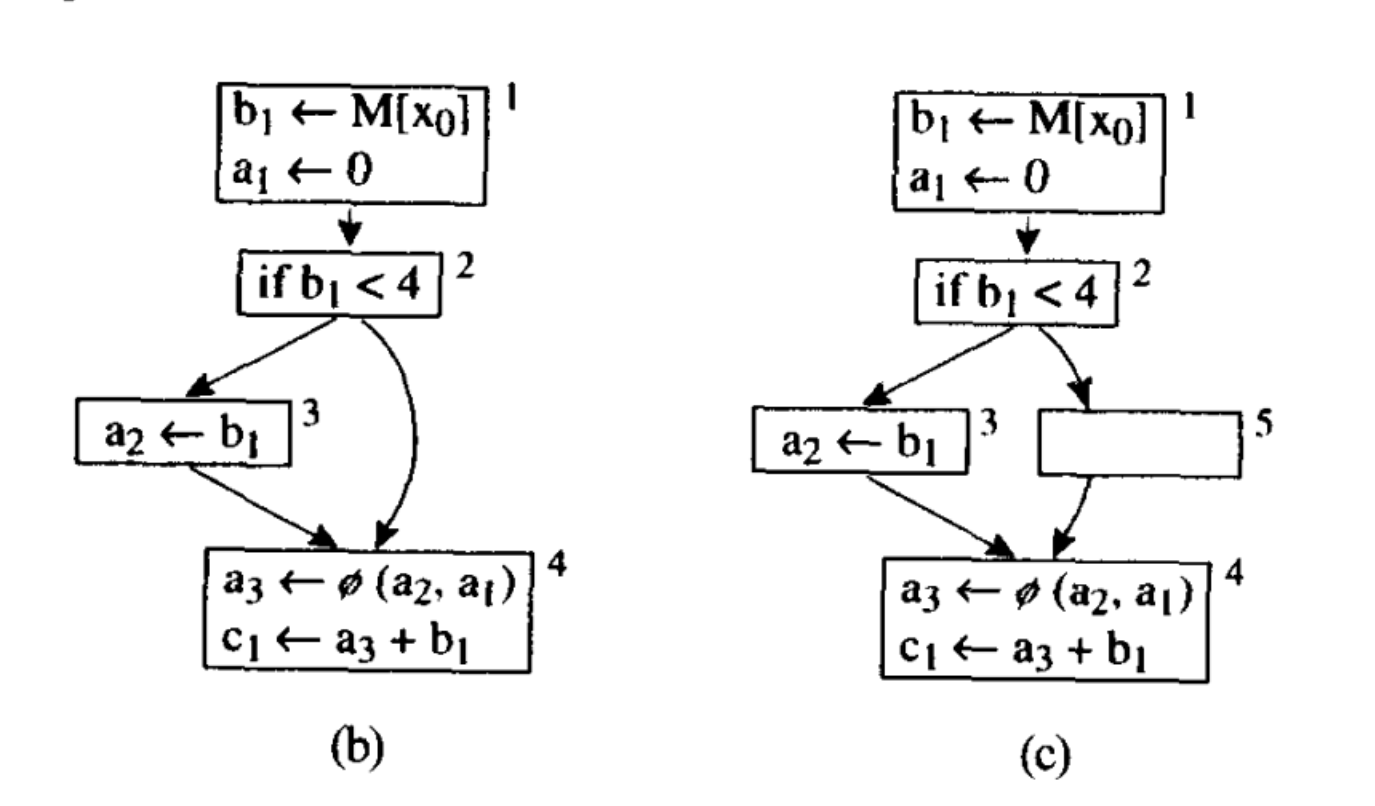
不做的话可能出现Lost copy problem
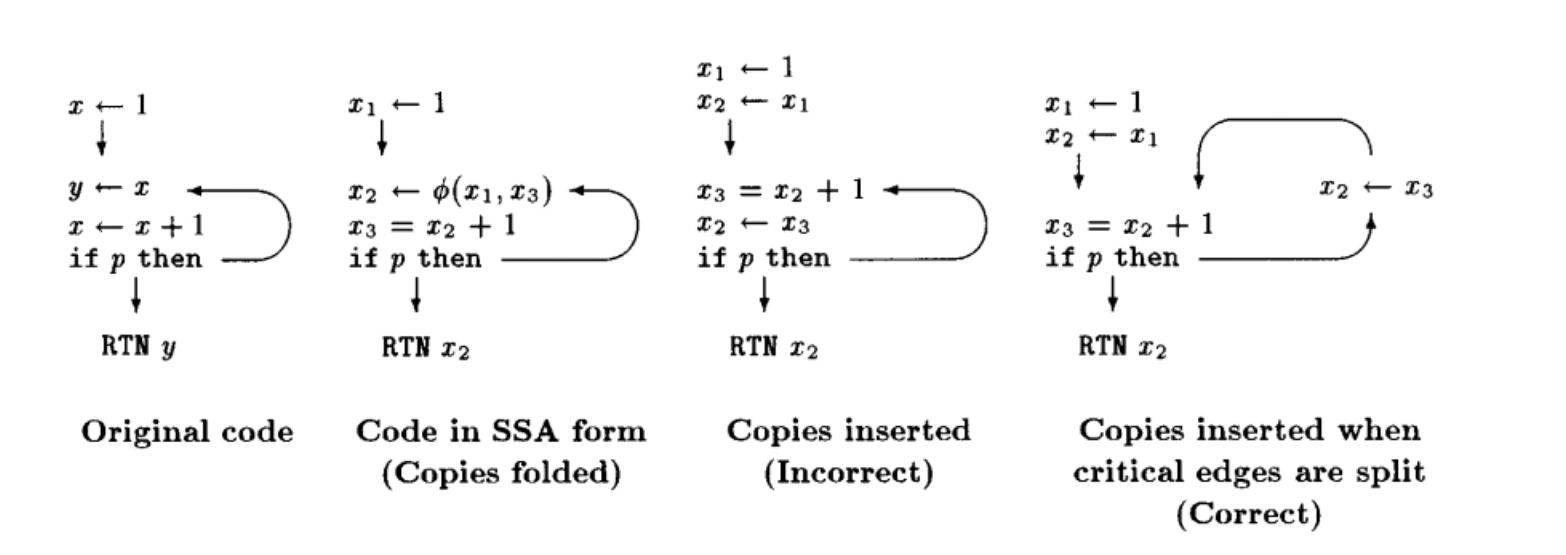
实现:
按ir顺序遍历每一个Block:
这个Block没有phi ir,直接进入copy环节
这个block有Phi ir,检测边分割:
如果它的前驱有true和false 2个后继,则就是critical edge,
加Block,然后调整块之间的关系
调整phiInfo里面的前驱块信息
(2) copy
和上面的边分割在一次循环里进行
遍历这个块的所有phi ir,如果phi里面的define value不等于phi左值(不是自引用情况),就insertCopy
insertCopy:block为phi的pair的from,dest为phi ir的左值,src为pair的define value,插入到pair的from的块中
// 针对的是需要拷贝回原来的
void insertCopies(BasicBlock *block,Value *dest,Value *src){
//有可能是最后一个基本块我们需要判断是branch语句或者jump语句前面
InstNode *tailIns = block->tail_node;
while(tailIns->inst->Opcode != br && tailIns->inst->Opcode != br_i1){
tailIns = get_prev_inst(tailIns);
}
//assert(tailIns != NULL);
InstNode *copyIns = newCopyOperation(src);
//assert(copyIns != NULL);
copyIns->inst->Parent = block;
Value *insValue = ins_get_dest(copyIns->inst);
insValue->alias = dest;
//应该不会超过10位数
// 针对这个情况好像没什么用
insValue->name = (char*)malloc(sizeof(char) * 10);
strcpy(insValue->name,"%copy");
ins_insert_before(copyIns,tailIns);
// 由于是CopyOperation 所以phi的type我们已经是设置好了的
}(3) sequentialize copies
什么时候需要这一步??感觉没有必要(swap problem)
一个基本块内有多个CopyOperation的话,如果出现b = a, c = b这种情况,需要处理
举例:
int main()
{
int a=getint(),b=getint();
while(1){
int x = a;
a = b;
b = x;
if(a > 2*b)
break;
}
return b + a;
}如果不加这步:
27(id) :9: ; preds = %3
41(id) : %4(%3) = %5
44(id) : %5(%2) = %4
28(id) : br label %3加之后:
27(id) :9: ; preds = %3
47(id) : %temp(%temp) = %5
48(id) : %5(%3) = %4
49(id) : %4(%2) = %temp
28(id) : br label %3
实现:
一个block一个block处理
对CopyOperation,先将src和dest组成一个CopyPair类型的元素加入pCopy这个hashSet,然后删掉这条ir,再seq的时候再加入
检测在这个block中,有没有CopyOperation的dest成了其他CopyOperation的src,将没有的先进入seq队列,并从pCopy删去。
将剩下的在pCopy中的pair按照else的做
将seq中的pair恢复成一条条的CopyOperation
资料引用:
虎书18-19章(《现代编译原理C语言描述》)
Tarjan算法理解:https://zhuanlan.zhihu.com/p/542396192
CSDN mem2reg源码解读:https://blog.csdn.net/a173373310/category_11246019.html
IDF相关论文:
算法:Vugranam C. Sreedhar and Guang R. Gao. A Linear Time Algorithm for Placing φ-Nodes
理论相关证明:Vugranam C. Sreedhar and Guang R. Gao. Computing φ-nodes in linear time using DJ-graphs.
semi-pruned与pruned SSA,与lost copy, swap problem:
论文:Practical Improvements to the Construction and Destruction of Static Single Assignment Form
SSA book三四章