CFL-Reachability面试准备
什么是CFL-Reachability problem?
CFL-Reachability是指选择两个节点A和B,只有当A和B路径边缘的label连接起来的word是符合CFL语言,是CFL语言合法的word时,才认为A和B是reachable。然后根据src和target提出了multi source/single source, multi target/single target任意组合的4种变体。
几句话来概括IFDS的思想
IFDS将经典数据流分析的IN-OUT/GEN以
集合传播数据流的方式,转换为图上的边(dataflow fact)的构造问题。(将经典数据流分析的Transfer Function转换为图可达/传递必包的问题)什么是传递闭包:
“传递闭包、即在数学中,在集合X上的二元关系R的传递闭包是包含R的X上的最小的传递关系。”
人话 : 建立传递闭包的过程,就是给定一个有向(无向)图,对于节点 i 和节点 j ,如果他们联通但不直接相连,我们就建一个 i 到 j 的边.
用图可达性来做的优点:
不是所有的path都是可执行的,本文提出的框架会只尽量沿着feasible的path分析,减少无关分析量。又比如右边的图,我们做上下文敏感的分析,最初基于克隆来做,在有深层次调用的情况下,不管是调用点敏感或者对象敏感,资源消耗特别大,一般会加上k层上下文这种限制,而用图可达性可以在消耗更小的资源的情况下做到更精准的分析结果。
为什么要选择上下文无关语言来实现呢?
需要配对,我们就想到了上下文无关语言,因为上下文无关语言与下推自动机具有语法上的等价性,而下推自动机PDA有一个栈,在状态转移时能帮助进行需要的配对,就比如开闭括号的配对,用这个栈,我们可以实现调用点与返回点配对的想法。

IFDS具体指的是什么意思?
interprocedural, finite, distributive, subset
这个框架能解决一类过程间数据流分析的子问题,这类问题的边转移和结点转移的流函数具有分配性,定义域是有限集。
distributive : 论文里面提到当需要考虑别名问题的时候,可能会损失精度。主要原因应该就是,我们使用的图支持的数据流输入因素只能有一个
什么是IFDS问题?

IFDS具体过程:
为程序建立一个超图
超图是一组控制流图,每一个控制流图都有自己独特的起始地点和结束结点,并且有三种表示过程调用的边。与过程间控制流图是很像的,主要就是将调用点拆分为了调用结点与返回结点两部分。
根据问题定义flow function
使用lambda表达式来标记流函数。流函数的输入是上一个程序点的数据流值,输出是本程序点的数据流值
将flow function转化为用二部图表示的代表关系
D并上0,D是指dataflow fact的集合,也是IFDS中finite的体现
0到0这样的边,并称作glue edge粘边,设计的缘由是如果没有像 0→0 这样的边,很多个二部图就没办法“粘”在一起了
再将二部图连起来形成一个exploded graph
至此程序分析就被完全转化为了一个图可达的问题,用tabulation算法就可以得到我们想要的分析结果
讲讲制表算法:
一些预备函数:
returnSite: 映射 call node -> 与之对应的return-site node
procOf: 映射 node -> 与之对应的enclosing函数
calledProc: 映射 call node -> callee的函数名
callers: 映射 函数名 -> 调用到该函数的call nodes

其中n这些是N* x {D并0},结点stmt+dataflow fact
注意source总是以<sp, d1>形式的节点(sp !)
工作表算法,将edge分三类讨论:
比如有<sp, d1> -> <n ,d2>
普通边:将<n, d2>指向的所有<m, d3>,propagate得到<sp, d1> -> <m, d3>
对于调用点call边:
call的调用边,在找到一个新的可达方法后,首先在这个新方法内加入自环边,这个作用是使得被调函数内的数据流传播是上下文无关的,分析了一次之后下一次该函数再被调用就不用分析。然后根据call-to-return边或者摘要边让调用返回处可达
返回边:
首先根据call边与return边,在这之间建立一个摘要边,总结函数调用的结果。
然后传播一下摘要出的东西:
其中Scall这个callee的procOf就是调用它的main

下一次再想看这个被调函数直接看摘要就好,不用再深入进去走走走,然后等到返回边又更新信息了
关于conditional edge:详见statement.pdf,第一轮做库函数摘要,从小摘要处慢慢往外扩散(比如从{扩散到S,然后+e越走越远);第二轮分析client,也是慢慢从能补上的premise(使得conditional edge变成unconditional edge),然后慢慢扩散越来越远吧
InterDyck:
SPDS-R为每个dyck language单独使用一个栈(并在处理一个phase时丢弃其他dyck的处理),如果每个phase都被判定为dyck-reachable,即可达。
LCL-R是将InterDyck可达性问题重新定义成一个等价的linear-conjunctive-language reachability problem,其中通过制表算法获得summaries。string s 可达可通过s1可达,s2可达,ab属于语言,s = s1 \cdot b = a \cdot s2决定
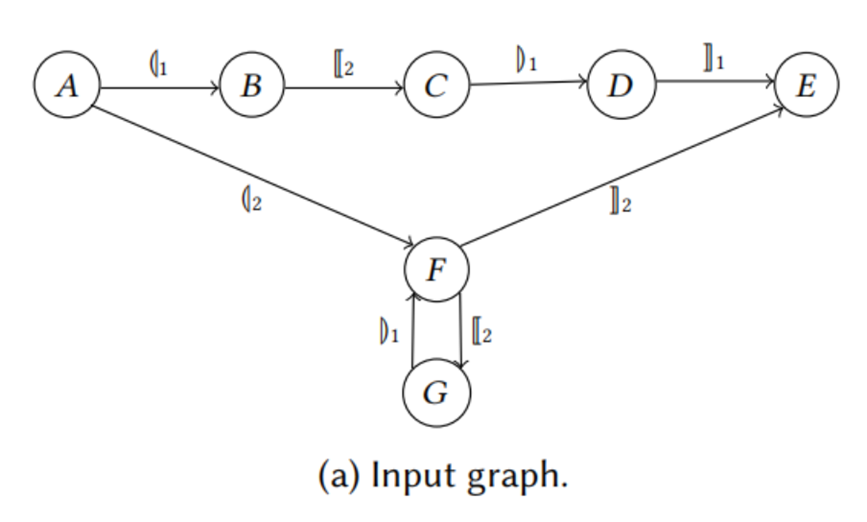
SPDS在这个例子中判定(A,E)可达,仅仅因为从平路分析()匹配,下面路分析[]匹配,每个dyck都匹配所以可达,感觉又没有注意顺序,又path不同不精确(这就叫不能distinguish paths吗)
LCL在这个例子中又有finite summary 近似(将(与((看作同一summary,因为不知道cycle数吧),又有A-D,F-E都可达,接上了A-E可达的路径不可辨析的imprecision